函数式编程笔记
面向对象编程讲究的是父子关系,继承封装多态。。。函数式编程讲究的是独立,是兄弟和兄弟的关系!
# 函数式编程思维
# 范畴论
- 函数式编程 -> 范畴论的数学分支 -> 人类世界上所有概念体系都可以抽象成范畴
- 构成范畴 -> 彼此之间存在联系、事物、对象 -> 关键是找出事物之间的关系
- 范畴论认为,同一个范畴的所有成员,就是不同形态的“变形”,通过“态射”,一个成员可以变成另一个成员
# 函数式编程基础理论
主旨:复杂的函数 -> (将过程描述成一系列嵌套的函数调用) -> 简单的函数
注意:函数式编程,即以数学的思维方式编程,将无法使用常规的逻辑判断(if else ...)
近几年因为react的 高阶函数 逐渐流行起来
# 基础知识
- 函数是一等公民:指的是函数与其他数据类型一样,处于平等地位,可以作为参数,也可以作为其他函数的返回值
- 不可改变量:变量仅仅代表某个表达式,不能被修改,所有变量只能被赋值一次
- 不修改状态,没有副作用:不修改系统状态,只是单纯的计算过程
- 引用透明:函数运行只依赖参数
# 常用核心概念
# 纯函数
所有计算过程均为纯函数,即同样的输入一定对应着同样的输出,没有任何可观测的副作用(不修改任何外部变量),也不依赖任何外部环境变量(环境变量有可能在系统运行的时候产生改变,导致函数运算结果发生改变),使用纯函数一个最直观的好处就是程序的可信程度大大提升,同时也更方便测试
优缺点:
- 优点:由于同样的输入一定对应着同样的输出,因此计算过的值便可以缓存起来,下次调用相同的函数只需从缓存中取,不需要重复计算
- 缺点:有些时候为了保证函数的纯度,会将一些值硬编码在函数体内,比如
const isAdult = age => age >= 18,这样导致拓展性较差。可以使用函数柯里化进行依赖包装来解决
幂等性:比纯函数的优先级还高,指的是执行无数次之后还有相同的效果,同一参数运行一次二次无数次的结果全部一致,例子: Math.abs(-54) ,执行结果永远为 54
# 偏函数
传递给函数一部分参数调用它,返回一个函数去处理剩下的参数,例子:
// 常规写法:
/**
* 判断年龄是否达标
* @param {Number} limit 标准
* @param {Number} age 年龄
*/
const isAgeReach = (limit, age) => age >= limit;
// 偏函数,一次只处理一个参数
const isAgeReach_partial = limit => age => age >= limit;
// 利用偏函数构造不同的工具
const isAdult = age => isAgeReach_partial(18)(age);
const isOld = age => isAgeReach_partial(70)(age);
相当利用闭包保存变量的能力,错开了参数的传递,使得每次就只处理一个参数,关注分离。 bind 就是一种偏函数
一个简单的偏函数方案:
const partial = (f, ...args) =>
(...moreArgs) =>
f(...args, ...moreArgs)
# 函数柯里化
柯里化(Curried)是一种“预加载”函数的方法,通过传递较少的参数,得到一个已经记住了这些参数的新函数。这是一种对参数的“缓存”(利用闭包)
柯里化是通过偏函数思想去实现的:
const curry = (fn, arity = fn.length) => {
// 1. 构造一个这样的函数:
// 即:接收前一部分参数,返回一个 接收后一部分参数 的函数,返回的那个函数需在内部判断是否执行原函数
const nextCurried = (...prevArgs) =>
(...nextArgs) => {
const args = [ ...prevArgs, ...nextArgs ];
return args.length >= arity
? fn(...args)
: nextCurried(...args)
};
// 2. 将构造的这个函数执行并返回,初始入参为空
return nextCurried();
};
这个柯里化可以选择提供被柯里化函数的参数个数(默认为形参个数 fn.length ),即如果传入的参数达到这个个数,被柯里化的函数便会执行
利用柯里化函数分离参数:
function add(a, b, c) {
return a + b + c;
}
const _add = curry(add);
_add(1)(2)(3); // 6
_add(1, 2)(3); // 6
_add(1)(2, 3); // 6
_add(1, 2, 3); // 6
# 函数组合
之前说到函数式编程就是依靠将复杂的函数过程描述成一系列嵌套的函数调用,分离成简单的函数,那么想象一下调用形式:h(g(f())),这样就很容易写成洋葱式的代码,可读性很低,函数组合就是来解决这类问题的,例子:
const first = arr => arr[0];
const reverse = arr => arr.reverse();
const last = compose(first, reverse);
last([1, 2, 3, 4, 5]); // 5
一个简单的compose的实现:
const compose = (...fns) =>
fns.reduce((f, g) =>
(...args) => f(g(...args))
)
函数组合满足结合律,即:
compose(f, compose(g, h)) === compose(compose(f, g), h) === compose(f, g, h)
# Point Free
想象一下:map、reduce 这些数组方法在平时使用的时候都需要通过一个对象(中间变量)去挂载它:
// 通过实体
[ 1, 2, 3 ].map(x => x + 1); // [ 2, 3, 4 ]
// 通过变量
const arr = [ 1, 2, 3 ];
arr.map(x => x + 1); // [ 2, 3, 4 ]
但是这个中间变量只是传递了我们这个方法需要作用的目标,是一个转瞬即逝的变量,毫无意义
而 Point Free 风格的编码讲究的就是 map 就应该是一个独立的方法,作用的目标(arr)和方法(fn)都可以通过传参挂载进来,来看另一个例子:
// 面向对象风格:
const f = str => str.toUpperCase().split('');
// Point Free 风格
const toUpperCase = str => str.toUpperCase();
const split = x => str => str.split(x);
const f = compose(split(''), toUpperCase);
这里面相对象风格的方式,其内部的 toUpperCase , split 都是为 str 服务的,是一次性的,不方便进行更深的抽象和复用。
而Point Free 风格并不关心这个方法 f 最终作用的对象是啥,只是一个单纯的入参为 String ,出参为 Array 的方法,这样相当于提供了一个便于下一次组合的公共的纯函数,抽象了中间的逻辑,让代码保存简洁和通用
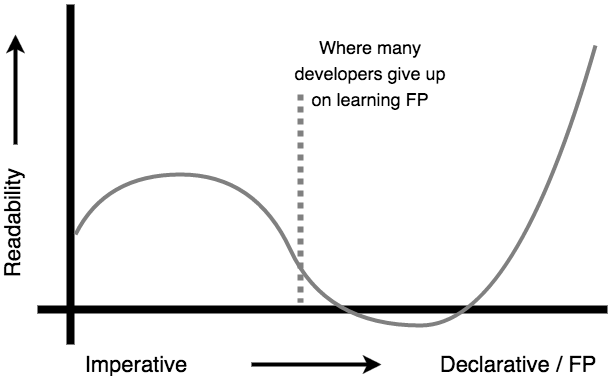
# 声明式与命令式代码
- 命令式的代码在于描述详细的操作步骤告诉计算机该怎么做,这是一种比较底层细节的描述形式,像
if语句和for循环这样的语句,这些语句旨在精确地指导计算机如何完成一件事情。 - 声明式的代码在于将细节做高度抽象,封装成一些声明式的操作,通过层层组合将这些操作拼在一起,构建应用程序,声明式代码更专注于描述最终的结果。
举个很形象的例子就是:
现在你要打造一辆汽车 (应用程序) ,你 (开发人员) 可以用一种将所有的零部件暴露在外,构成一个细节精致、组装结构清晰的命令式的方式;也可以用把所有零部件都隐藏在内部,将轮胎与整体车身结合的声明式的方式。这两种方式都可以打造一辆汽车,但是如果站在使用者 (同事) 的角度看待这辆汽车,他可能并不关系这辆汽车是如何打造的 (代码的具体实现细节) ,他只关心这辆车好不好用、性能以及速度如何 (封装的方法如何调用) 。所有的零部件暴露在外的方式 (命令式的代码) 反而增加了使用者的学习成本 (代码可读性) 。
这里附上声明式和命令式代码的可读性曲线:
# 专业术语
# 高阶函数
说白了就是一句话:输入函数,输出函数,并且让原来的函数增加功能,拥有更高的能力,例子:
// 接受俩值,返回这俩值的和
const add = (a, b) => a + b;
// 高阶函数
const math = func => arr => func(arr[0], arr[1]);
// 用高阶函数包装原函数,增强原函数功能并返回
const highOrderAdd = math(add);
// 原来的调用方式
add(1, 2); // 3
// 现在原函数可以接受数组了!
highOrderAdd([1, 2]); // 3
高阶函数体现的函数式编程:
- 函数是一等公民
- 高阶函数以一个函数作为参数
- 高阶函数以一个函数作为返回值
# 尾调用优化
注意:
- 浏览器目前并没有实现尾调用优化!现在通俗说的尾调用优化都是自己通过写代码的方式去改善原有函数的执行方式,实现了或者说是模拟了尾调用优化,并没有实现游览器的尾调用优化。尾递归调用优化是浏览器实现的,目前只有Safari部署了,V8引擎实际上已经实现了尾调用优化,但是默认是关闭该功能的。据说可以用元编程的方式开启尾递归调用优化
- 还有一点需要说明的是,浏览器爆栈跟死循环是两个概念:死循环是浏览器卡住,主线程被占死了,并没有报错。而爆栈是浏览器报的错误,分配的内存大小用没了,报错。但是造成的效果是一样的都是浏览器无法响应了
先来看传统递归:
function sum (n) {
if (n === 1) return 1;
return n + sum(n - 1);
}
我们可以写出以上代码执行的堆栈占用过程:
sum(5)
(5 + sum(4))
(5 + (4 + sum(3)))
(5 + (4 + (3 + sum(2))))
(5 + (4 + (3 + (2 + sum(1)))))
(5 + (4 + (3 + (2 + 1))))
(5 + (4 + (3 + 3)))
(5 + (4 + 6))
(5 + 10)
15
可以看到,内存需要记录调用的堆栈所处的深度和位置信息,在最底层计算返回值,再依次一层层跳回到上一层,直至最外层的调用函数。这样CPU的计算和内存消耗会很多,而且当深度过大时,会出现堆栈溢出
可以用尾递归优化以上代码:
function sum (x, total) {
if (x === 1) return x + total;
return sum(x - 1, x + total);
}
优化之后的代码,整个计算过程是线性的,调用一次 sum(x, tatol) 后,会进入下一个栈,相关的数据信息会跟随进入,不再放在堆栈上保存,相当于是用于计算sum的浏览器堆栈一直就只有一层!但是注意和尾递归调用优化的区别,这里虽然确实减少了一些堆栈的存贮,但是每一次执行sum,依旧为每次执行创建了单次的执行帧(可以使用 console.trace() 查看调用帧)。
在 ES6 出来之前,JavaScript 对尾调用一直没明确规定(也没有禁用)。ES6 明确规定了 PTC 的特定形式,在 ES6 中,只要使用尾调用,就不会发生栈溢出。实际上这也就意味着,只要正确的使用 PTC,就不会抛出 RangeError 这样的异常错误。
下面这些不能称作尾调用(PTC)
sum();
return;
// 或
const x = sum( .. );
return x;
// 或
return 1 + sum( .. );
但是这种是PTC:
// x 进行条件判断之后,或执行 foo(..),或执行 bar(..),不论执行哪个,返回结果都会被 return 返回掉。这个例子符合 PTC 规范。
return x ? sum( .. ) : sum1( .. );
再次声明:这叫尾递归,不叫尾递归调用优化,不是浏览器实现的🤪
# 容器、函子
- 容器:我们可以将“范畴”想象成一个容器,容器内包含俩内容,一个是容器的值(value),一个是值的变形关系,或者说函数。
- 函子:如果容器能够接受一个变形关系,依次作用域容器上的值,将当前容器变形成另一个容器,这就构成了函子(redux核心原理就是这样)
容器:
一般会有一个of方法,用来生成容器实例,相当于一个工厂模式
class Container {
constructor(val) {
this.val = val;
}
}
// 这里将 of 挂载在实例上,为的是让它看起来不那么面向对象
Container.of = function (val) {
return new Container(val);
}
Functor函子:
Functor是一个队函数调用的抽象,赋予容器自己去调用函数的能力。一般都提供一个map接口,传入一个函数(变形关系),让容器自己去在一定时机调操作这个函数,这样有产生了一些惰性求值,错误处理,异步调用等非常实用的特性
class Functor extends Container {
map(f) {
return Functor.of(f(this.val));
}
}
vuex、reduxm,都是这样的原理,输入一个值,返回一个新的对象。
注意:
这里的 map 跟 Array.prototype.map 不是一回事,注意区分
Maybe函子(if):
Maybe函子就是传统意义上的if
class Maybe extends Functor {
map(f) {
return this.val ? Maybe.of(f(this.val)) : Maybe.of(null);
}
}
Either函子:
用来代替错误处理,try catch 不纯,因为错误时在catch会捕获到 e
class Either extends Functor {
constructor(left, right) {
this.left = left;
this.right = right;
}
map(f) {
return this.right
? Either.of(this.left, f(this.right))
: Either.of(f(this.left), this.right)
}
}
# IO、Monad
终于到了最恶心的部分了🤯🤯🤯,我努力给自己整明白。。。
理想总是美好的,现实总是骨感的,我们之前讨论的一大堆内容都是建立在 “纯” 的基础上的,意味着这里只有计算,没有任何与外部变量的数据交换。
然而,一个永远不与外界交互的应用,真的有存在的价值嘛?就好比一个哲学问题:如果沙漠中的一棵树被风吹动了,但是没有人看到,那么这棵树到底是动了还是没动呢?
回到主题:
正真的程序总是要去接触肮脏的世界的: window.localStorage() 、 fs.readFile() 、 console.log() ,在我们的程序中大量充斥着 “脏” 的操作。
有什么办法可以规避这个问题呢?有的,IO函子正是用来解决这类问题,想象如下场景:
如果一个函数存在副作用:
const impureAddOne = x => {
console.log('add one!')
return x + 1
}
我们做个弊,给这个不纯的函数外面再包装一层:
const impureAddOne = () = x => {
console.log('add one!')
return x + 1
}
修改后的函数,提供同样的参数,每次执行他们都返回同样的函数,可以做到引用透明。这!!也是纯的!!
现在我们得到结论,如果将不纯的操作后置,那么调用这个函数之前都可以保证是纯的,接下来看IO函子:
class IO extends Functor {
//val是最初的脏操作
static of (val) {
return new IO(val);
}
map(f) {
return IO.of(compose(f, this.val))
}
run(x) {
return this.val(x)
}
}
注意看这里的 map ,它只是单纯的将传入的脏操作与新传入的函数组合起来了,构成一个新的嵌套调用链,并包装成新的IO函子返回了,注意这里只是组合起来了,并没有执行这一步脏操作。
同时这里有一个 run 方法,代表的是将这份脏操作真正的执行!这里的意义就在于,将脏操作包装起来之后,函数整体是纯的,而真正不纯的操作留到最后 run 的时候去做了!!
下面我们使用一下这个函子:
const impureAddOne = x => {
console.log('add one!')
return x + 1
}
const impureMultiplyByTwo = x => {
console.log('multiply by two!')
return 2 * x
}
IO.of(impureAddOne)
.map(impureMultiplyByTwo)
.run(2)
// add one!
// multiply by two!
// 6
这便是IO函子的意义!
OK!这里我们看到使用IO函子的使用,但是想象一下,我们这里每次 map 都包装一个新的IO函子返回,这也意味着当我们函数组合的时候,在执行完一个操作之后我们需要通过 run 将包装拆开,将里面的值取出,作为下一个函数的入参,再进行包装,这也未免太过麻烦,每次函数组合都需要map再run,有什么办法可以做到一步操作完成两件事情呢?下面 monad 登场!!!
Mona就是一种设计模式,表示将一个运算过程,通过函数拆解成互相连接的多个步骤。只需提供下一步运算所需的函数,整个运算就会自动运行下去。
//Monad 函子
class Monad extends Functor {
join() {
return this.val;
}
flatMap(f) {
return Monad.of(compose(f, this.val)).join();
}
}
可以这样理解:如果我们将一个初始的容器map包装两次,相当于现在我的 “容器” 内的值还是个 “容器” ,如果我再去函数组合,入参是 “容器” ,这样但是无法操作的,所以我们需要使用 monad函子 的 flatMap 去包装下一个变形关系,即将组合后的容器的容器拆箱并执行,返回只有一层容器包装的函子!!
不容易啊!!🤕🤕🤕
# 流行的几大函数式编程库
- RxJS
- cycleJs
- lodashJS、lazy
- underscoreJS
- ramdajs
# 资源
- JavaScript轻量级函数式编程Functional-Light-JS,掘金上面有的译文
- 完整解释 Monad -- 程序员范畴论入门
- RxJS原理解析之自己造一个
共勉!!