可视化埋点JS-SDK技术方案
# 感性认识
现阶段对于用户行为收集的方式,大抵分为三种:
- 埋点上报:前端开发人员在代码中添加需要收集的数据信息,上报给服务。这种方式的优点是数据收集的很全,并且数据来源比较灵活,缺点是开发人员的工作量会比较大,并且对于一些历史项目不太友好。
- 全埋点:通过添加一段js脚本,给页面上几乎所有(实际上是大多数常用的事件,记录dom的所有事件是不现实的)的事件绑定监听,记录全量日志。这种方式的局限性比较大,数据收集的目的性不强,并且有可能收集不全。
- 可视化埋点:通过一种可视化的配置界面,提供给开发人员或者是业务工作人员自定义配置的能力,同时在用户使用的时候添加相应的事件监听。这种方式的好处是开发人员在代码方面的工作比较轻量,只需要引入一段js脚本,并且对配置人员的代码熟悉程度要求不高,缺点是数据收集完全依赖于配置,没有配置的用户行为完全监控不了,这对于产品的优化方面并不友好(可能由于界面设计或者交互体验的问题,用户在某个业务线上来回折腾,而迟迟不能完成功能,这种行为监控起来就比较麻烦了)。
上面的三种情况各有利弊,综合考虑,我们尝试采用 全埋点 加 可视化埋点 的组合方案,即在收集全量日志的同时,配合可视化埋点的配置整合起来,上报给服务。
# 两种模式
由于目标页面需要兼顾行为收集和配置添加,因此在JS-SDK内部存在两种模式:埋点模式 和 配置模式。
# 埋点模式
当JS-SDK初始化的时候,会首先去拿一次配置信息,再给整个document的submit、change、click等一系列事件设置监听器,同时比较配置信息和添加的默认埋点事件比较,将需要特殊记录的事件绑定单独的监听器。当document的监听器监听到绑定的事件时,会先根据event.target去拿到当前目标元素的id,与配置信息比较,区分普通事件和特殊事件上报给服务。
# 配置模式
可视化配置页开启配置的方式是用一个iframe去加载目标页,并且配置页和目标页的数据通信通过postmassage来完成(需指定origin)。
开启配置模式需要在配置页的iframe添加对应的签名作为query,并且出于安全考虑,JS-SDK只负责在配置的时候高亮显示目标元素,而目标元素对应的事件信息的添加以及保存,全部交由配置页处理。
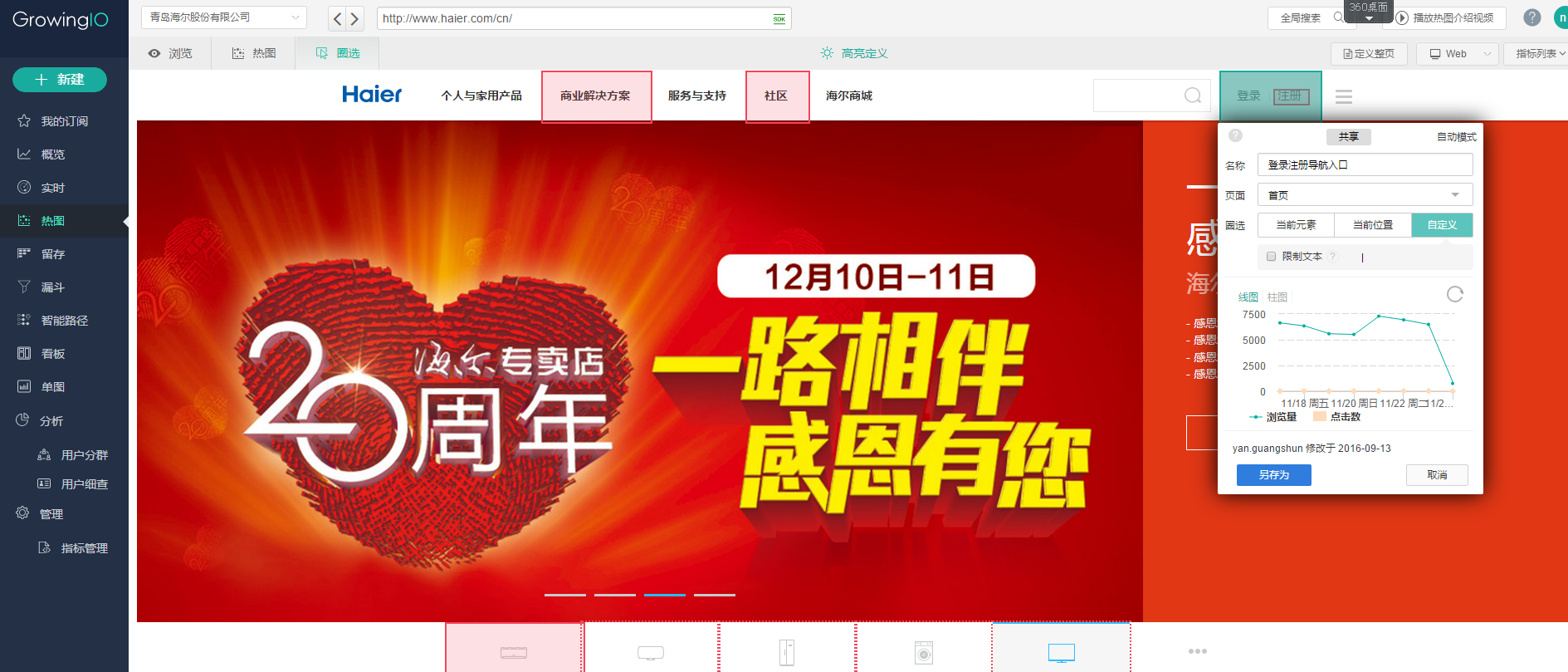
这里附上GrowingIO的可视化配置截图:
# 元素定位策略
对于用户行为的触发单元,元素定位是必不可少的,我们需要确定到页面上的某个唯一的元素并拿到它的 ID(此处的id类似于元素的签名,并非css的id选择器),之前想要用 XPath 作为元素的签名,但是如果页面嵌套过深,XPath会很长,在服务记录的时候比较消耗资源,后来参考了 whats-element 的方式,并做了一些优化处理。
通过对 whats-element 的源码分析,大致思路如下:
- 检查Ele是否是HTMLElement
- 检查是否存在id
- 若上一步未命中,检查是否存在name
- 若上一步未命中,检查是否有className
- 若上一步未命中,用混合查找的方式查找
- 若上一步未命中,用querySelectorAll命中所有的元素,遍历过滤
- 若上一步未命中,用递归的方式查找父级,再用querySelectorAll命中所有的元素,遍历过滤
可以看到任何一个步骤只要命中了目标元素,后面的就直接跳过,并且每一个步骤都是越来越深层次的匹配。其目的就是尽量收集到更少更简单的元素信息,并且又能拿到唯一代表一个元素的句柄。
以下为源码部分:(为了方便阅读,只提取关键代码)
whatsElementPure.prototype.getUniqueId = function (element, parent) {
// 输入:event.target,作为 element
if(!(element instanceof HTMLElement)){
// 1. 检查Ele是否是HTMLElement
return {}
}
// 初始化配置
var result = {
wid: '',
type: '',
// ...
}
// 2. 检查是否存在id
if (id && document.getElementById(id) === element) {
// 判断:getElementById(id) === Ele
result.wid = `${tag}#${id}`
result.type = 'document.getElementById()'
}
// 3. 检查是否存在name
if (!result.wid && name && document.getElementsByName(name)[0] === element) {
// 判断:getElementsByName(name)[0] === Ele
result.wid = name
result.type = 'document.getElementsByName()'
}
// 4. 检查是否有className
if (!result.wid && className && document.querySelector(tag+className) === element) {
// 判断:querySelector(tag+className) === Ele
result.wid = tag+className
result.type = 'document.querySelector()'
}
// 5. 用混合查找的方式
if (!result.wid) {
// 拼接tag+name+className
queryString = tag;
queryString = queryString + className
queryString = `${queryString}[name='${name}']`
if (whatsElementPure.prototype.getTarget(queryString) === element) {
result.wid = queryString
result.type = 'document.querySelector()'
}
}
// 6. 用querySelectorAll命中所有的元素,遍历过滤
if (!result.wid) {
// 拼接tag+className
queryString = tag
queryString = `${queryString}${className}`
var elements = document.querySelectorAll(queryString)
// 遍历匹配querySelector(queryString+:nth-child("+index+")) === Ele
queryString = `${queryString}:nth-child(${index})`
result.wid = queryString
result.type = 'document.querySelector()'
}
// 7. 用递归的方式查找父级,再用querySelectorAll命中所有的元素,遍历过滤
if (!result.wid) {
// 递归拿到父级句柄
var parentQueryResult = whatsElementPure.prototype.getUniqueId(element.parentNode, true)
parentQueryString = parentQueryResult.wid
// 拼接父子句柄
var queryString = `${parentQueryString}>${tag}`
var queryElements = document.querySelectorAll(queryString)
// 遍历匹配querySelector(parentQueryString+">"+queryString+:nth-child("+index+")) === Ele
queryString = `${parentQueryString}>${tag}:nth-child(${index})`
result.wid = queryString
result.type = 'document.querySelector()'
}
// 输出结果
return result
}
// 混合方式查找
whatsElementPure.prototype.getTarget = function (queryString) {
return document.getElementById(queryString) || document.getElementsByName(queryString)[0] || document.querySelector(queryString)
}
可以看到想要定位一个元素,实际上不一定需要拿到元素完整的 XPath ,我们只要获取到某个签名串,能够通过浏览器的DOM操作API拿到唯一一个元素,这就是我们想要的元素 ID。
# 全埋点事件监听
想要记录全量日志,就需要对于各种dom事件添加监控,这些事件可以大致分为 瞬发事件 和 持续事件 。这里我们提供了一些基础事件的监控:
# 瞬发
- load:加载事件
- online / offline:连线、离线状态事件
- focus / blur:焦点聚集、焦点失去事件,(过滤出
input/textarea) - click / dblclick:单击、双击事件,(过滤出
a/input/button) - play / pause:播放、暂停事件,(过滤出
video/audio) - popstate / hashchange:路由变化事件
# 持续
- change:输入事件,(过滤出
input/textarea) - touchmove:滑动事件
注意:
由于记录全量日志,对于服务的压力会比较大,因此持续事件的记录需要做限流处理(如滚动事件200ms记录一次,输入事件在停止输入之后的300ms后记录一次,具体情况具体分析)。
# Event事件模型
这里我们参考了神策的 Event-User 事件模型。
一个 Event 就是描述了:一个用户在某个时间点、某个地方,以某种方式完成了某个具体的事情。
从这可以看出,一个完整的Event,包含如下的几个关键因素:
# who
即参与这个事件的用户是谁。根据我们的实际情况,我们使用 primary_id 来设置用户的唯一的cookie作为匿名 ID。同时我们也会去抓取 location.query 里面的 openId 字段(如果能正常获取到),上报nginx日志,作为在spark数据聚合处理阶段阶段,关联上用户五要素使用,形成完整的用户视图。
# when
即这个事件发生的实际时间。在我们的数据接口中,会同时记录服务端和客户端的时间,前者作为统一时间线,后者提供给某些记录时长的数据使用,二者都精确到毫秒。
# where
即事件发生的地点。nginx日志会记录用户访问时候的IP地址,根据IP我们可以获取到用户的具体地址、经纬度等信息。
# how
即用户从事这个事件的方式。这个概念就比较广了,包括用户使用的设备、使用的浏览器、操作系统版本、进入的渠道、跳转过来时的 referer 等。
1. $browser: 浏览器信息,字符串类型,如"Chrome"。
2. $model: 设备型号,字符串类型,如"iphone6"。
3. $os: 操作系统,字符串类型,如"iOS"。
4. $os_version: 操作系统版本,字符串类型,如"8.1.1"。
5. $screen_height: 屏幕高度,数字类型,如1920。
6. $screen_width: 屏幕宽度,数字类型,如1080。
7. $wifi: 是否 WIFI,BOOL类型,如true。
# what
描述用户所做的这个事件的具体内容。在我们的数据接口中,首先是使用 event 记录当前触发的dom事件名称,来对用户所做的内容做初步的分类。后续在可视化配置阶段会提供给配置人员设置特殊事件(附带感情色彩的事件,可以是用户某个具体行为的目的,也可以是各种业务相关的功能事件)的入口。下面给出一些典型的例子:
1. 对于一个“购买”类型的事件,则可能需要记录的字段有:商品名称、商品类型、购买数量、购买金额、付款方式等。
2. 对于一个“搜索”类型的事件,则可能需要记录的字段有:搜索关键词、搜索类型等。
3. 对于一个“填写表格”类型的事件,则可能需要记录的字段有:表格类型、表格关键信息等。
4. 对于一个“用户注册”类型的事件,则可能需要记录的字段有:注册渠道、用户基本信息等。
# 整体流程
根据以上各技术细节的描述,可将整体流程概括为两方面:
行为记录:
- JS-SDK被添加进目标页面,初始化。
- 读取配置信息json,配合全埋点的默认事件,给目标页面元素绑定上对应的监听。
- 用户触发某个功能埋点,JS-SDK请求一张1*1大小的gif,并附带相应的数据,在nginx保存一条日志。
配置:
- 配置人员打开目标界面。
- 输入URL,打开目标页面。
- 开启配置功能,选择目标元素。
- 添加相应事件信息。
- 点击保存配置,将配置信息json保存在服务某处。
# 总结
无埋点用户行为收集实际上并非无埋点,而是通过可视化配置埋点的方式将需要记录的具体用户行为做抽象,达到收集的数据更具有目的性,并且最大限度的减轻人力成本的目的。数据收集的准确度直接影响后续数据分析的结果,我们需要在后续的开发和维护中根据具体细节作出相应调整。
← RxJS的响应式原理 目录 →