js模块化
# js模块化的意义
- 提供了一种更好的方式来组织变量和函数
- 解决命名冲突问题
- 解决变量共享问题
- 解决
<script>顺序排列难以维护的问题 - 解决变量存在于全局作用域,任何代码都可以改变的问题
# js模块化演进历史
- 1999 :: 直接定义依赖
由于 js 在设计之初的定位,基本没有模块化的概念 - 2003 :: 闭包模块化模式
通过 IFEE 及 闭包,简单解决私有变量的需求 - 2003 - 2009 :: 模版依赖 、 注释依赖 、 外部依赖 、 Sandbox
这段时间出现了五花八门的模块化思路,但是都存在种种可维护性问题,都没有解决根本问题 - 2009 :: 依赖注入
由 angular1.0 引入前端领域,但是依赖注入和解决模块化问题还差得远 - 2009 :: CommonJS
nodeJs 的出现,带来了真正意义上的模块化方案 CommonJS(服务端代码需要跟本地文件系统交互,跟网络层面交互,模块化成为必然)
真正解决模块化问题,后从 node 端逐渐发力到前端,前端需要使用构建工具模拟。 - 2009 :: AMD 、 CMD
将 node 层面的 CommonJS 模块化方式在前端模拟,由于 node 是同步的引用本地文件,而在前端需要依靠 http 请求获取资源,实现的是一种异步的资源获取,二者实现的理念不同 - 2011 :: UMD
同时兼容浏览器端与服务端的模块化方案,核心思想是,如果在 commonjs 环境(存在 module.exports,不存在 define),将函数执行结果交给 module.exports 实现 Commonjs,否则用 Amd 环境的 define,实现 Amd - 2015 :: ES2015 Modules
目前官方实现的模块化方案,之前的方案都是建立在运行时层面的,esm 是在编译期间的方案,目前还没有被浏览器实现,需要通过构建工具编译提供支持
# AMD & CMD
# AMD
AMD规范采用异步方式加载模块,模块的加载不影响它后面语句的运行。所有依赖这个模块的语句,都定义在一个回调函数中,等到加载完成之后,这个回调函数才会运行。
- 代表:
require.js - 核心思想:依赖前置
# 整体概念
D 模块依赖了 A、B、C 三个模块,顺序将是 加载并执行 A -> 加载并执行 B -> 加载并执行 C -> 执行 D
# 简单使用
- 定义模块
/**
* define(dependencs?: Array<string>, initial: Object | Function)
*/
// 直接定义一个对象
define({
color: 'black',
size: 'unisize'
});
// 通过函数返回一个对象
define(function () {
// Do something here ...
return {
color: 'black',
size: 'unisize'
}
});
// 定义有依赖项的模块
define([ './cart', './inventory' ], function(cart, inventory) {
// return an object to define the 'my/shirt' module.
return {
color: 'blue',
size: 'large',
addToCart: function() {
inventory.decrement(this);
cart.add(this);
}
};
});
- 导入模块
// 导入一个模块
require([ 'foo' ], function(foo) {
// do something
});
// 导入多个模块
require([ 'foo', 'bar' ], function(foo, bar) {
// do something
});
# require.js 源码分析
每读取到一段逻辑之前,先将所依赖的所有模块读取加载,并且维护一份已经加载的模块的缓存池,读取完成之后再执行该逻辑。
一个文件即为一个模块,模块与模块之间可以依赖,也可以毫无干系。
1. require 同时作为导入的函数(require),也作为定义的函数(define)
2. 只有模块被作为依赖时,才会被通过 script 标签载入到文件节点,同时缓存进模块缓存池
3. 模块的数据结构上有 onload API,保存了一系列依赖于该模块的代码片段,相当于各个通过 require 的代码片段之间加载阶段是不阻塞的,在依赖加载完全之后才会执行回调队列
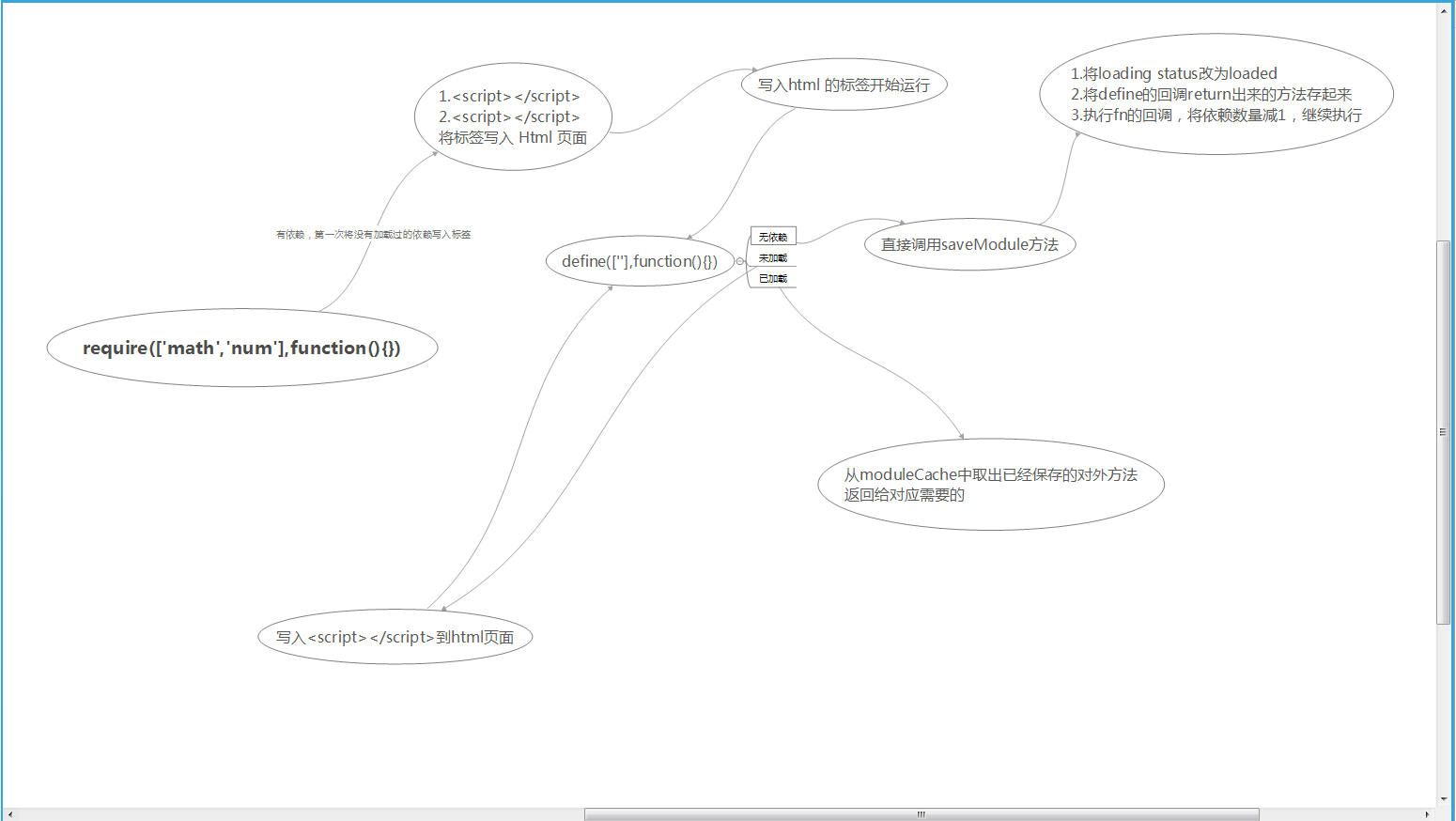
# 部分源码:
(function(){
// 维护的模块缓存池
var moduleCache = {};
/**
* require
* 同时作为导入的函数(require),也作为定义的函数(define)
* 只有模块被作为依赖时,才会被缓存进模块缓存池
*/
var require = function(deps, callback) {
var params = []; // 依赖加载后导出的 API 数组,后续会作为参数在执行回调的时候传入
var depCount = 0; // 异步加载模块的哨兵变量
// 当前模块名称
// require 作为导入模块时为'REQUIRE_MAIN',作为定义的模块时为模块 id
modName = document.currentScript && document.currentScript.id || 'REQUIRE_MAIN';
// 若存在相关依赖模块
if (deps.length) {
// 依次异步的加载模块,并将模块缓存进模块缓存池
for(i = 0, len = deps.length; i<len; i++) {
(function(i){
depCount++;
/**
* 这里是关键 !!
* 模块作为依赖时才会执行 loadMod ,缓存进模块缓存池
* 相关依赖加载完全之后,执行回调工厂
*/
loadMod(deps[i],function(param) {
depCount--;
if (depCount == 0) {
saveModule(modName, params, callback);
}
});
})(i)
}
} else {
isEmpty = true;
}
if (isEmpty) {
// 在下一个宏任务中执行回调
setTimeout(function() {
saveModule(modName, null, callback);
}, 0);
}
}
/**
* 加载模块,相当于由 define 定义的模块,需要通过 script 标签加载,并保存进模块缓存池
*/
var loadMod = function(modName, callback) {
// 模块数据结构:
// {
// modName: 模块名称
// status: 加载状态
// export: 模块需要导出的 API(若存在)
// onload: 模块加载完成后需要执行的回调队列,相当于保存了一系列依赖于该模块的代码片段
// }
if (moduleCache[modName]) {
// 模块缓存池已存在
if (mod.status == 'loaded') {
// 模块已加载完全,说明此时该模块以及相关依赖均加载完成,在下一个宏任务中执行回调
} else {
// 加载中状态,将回调添加进模块的 onload 回调队列
}
} else {
// 模块未加载
// 加载方式为添加 script 标签,异步加载模块代码
// 将模块保存进模块缓存池
}
};
/**
* 模块依赖初始化完成之后的回调工厂
* 作为依赖的模块会执行 onload 队列,相当于多个回调
* 只作为导入的代码片段的模块,直接执行回调
*/
var saveModule = function(modName, params, callback) {
if (moduleCache.hasOwnProperty(modName)) {
// 模块已存在于模块缓存池
// 意味着该模块为定义的模块,执行该模块的初始化工作,依次执行 onload 队列
} else {
// 未存在
// 意味着该模块为单纯的导入模块,直接执行回调
}
};
// 导出 require 和 define 方法
window.require = require;
window.define = require;
})();
# CMD
最贴近CommonJS的浏览器端异步模块化方案,简单的去除define的外包装,就是标准的CommonJS实现
CMD 规范中(前身为Modules/Wrappings规范),定义一个模块就是一个文件,形式为 define(factory) ,factory 即为定义模块的工厂函数,描述一份模块的初始化及导出部分。
factory 为模块运行时提供 require, exports, module ,作为模块向外提供的接口。
- 代表:
Sea.js - 核心思想:依赖后置 、即用即加载
- 整体概念:在模块定义中,使用到某块依赖时才去手动导入,即 即用即加载
# 简单使用(Sea.js 为例)
// 所有模块都通过 define 来定义
define(function(require, exports, module) {
// 通过 require 引入依赖,获取模块 a 的接口
var a = require('./a');
// 调用模块 a 的方法
a.doSomething();
// 通过 exports 对外提供接口foo 属性
exports.foo = 'bar';
// 对外提供 doSomething 方法
exports.doSomething = function() {};
// 错误用法!!!
exports = {
foo: 'bar',
doSomething: function() {}
};
// 正确写法,通过module.exports提供整个接口
module.exports = {
foo: 'bar',
doSomething: function() {}
};
});
// factory 为对象
define({ "foo": "bar" });
// factory 为函数
define(function(require, exports, module) {
// 模块代码
});
# Sea.js
Sea.js 更多的借鉴了 Modules/2.0 及 Modules/Transport 规范,即为 CMD 模块命名,使得 CMD 模块可以合并成JS文件,形式为 define(id?, deps?, factory) ,通过定义的 id 来缓存模块。
Sea.js 注意点:
- 一个模块就是一个文件,当一个文件里有多个 define 时,
v1.3.1之前默认将第一个define里的模块作为主模块进行返回,之后的版本只有最后一个定义的 CMD 模块会被识别,前面定义的模块都被它覆盖了 - 若没有显示的指明 id ,SeaJS 会用这个js文件的url作为它的 id
# factory 的三个参数
require: Function,同步获取其他模块提供的接口- require的模块不能被返回时,应该返回 null
- require.async(id, callback?),用来异步加载模块,加载失败时,callback 的形参为 null
- require.resolve(id),用来返回解析后的绝对路径
- 条件加载时如
var func = someExpResult ? require("play") : require("work");,浏览器会将两个模块文件都下载下来,建议使用 require.async 条件加载
exports: Object,仅仅是 module.exports 的一个引用,在模块内部对外提供接口module: Object,模板引用- module.url 解析后的绝对路径
- module.dependencies 模块依赖
- module.exports 暴露模块接口数据,也可以通过 return 直接提供接口
# Sea.js 模块加载大致流程
SeaJS 通过 factory.toString() 拿到源码,再通过正则匹配 require 的方式来得到依赖信息。
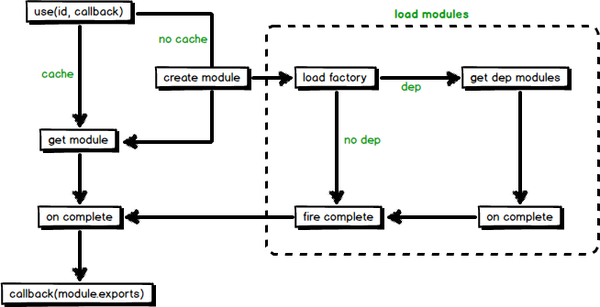
- 通过 use 方法来加载入口模块,并接收一个回调函数, 当模块加载完成, 会调用回调函数,并传入对应的模块作为参数。
- 从缓存或创建并加载 来获取到模块后,等待模块(包括模块依赖的模块)加载完成会调用回调函数。
- 在图片虚线部分中,加载factory及分析出模块的依赖,按依赖关系递归执行 document.createElement(‘script’) 。
# AMD vs CMD
AMD 与 CMD (RequireJS 与 Sea.js)的主要区别:
- 模块加载的时机不同
- RequireJS - 旨在 依赖前置 ,会先加载并执行全部依赖,再执行模块
- Sea.js - 旨在 即用即加载 ,在模块加载运行的时候依赖了某其他模块,同步加载该依赖,加载完毕后再继续执行后续模块
- 依赖加载错误时需要的处理方式不同
- RequireJS - 依赖加载阶段,意味着所提供支持的模块还未执行任何操作,无需考虑回滚操作
- Sea.js - 依赖加载出错,所提供支持的模块可能已经执行了某操作,需考虑回滚操作
- 设计理念不同
- RequireJS - require 使用方法特别灵活
require('a') // -- gets exports of module a require(['a']) // -- fetch module a according to module name scheme require(['a.js']) // -- fetch a.js directly relative to current page require({...}) // -- set loader config - Sea.js - 努力保持简单,并支持 CSS 模块的加载
- 保持简单,职责单一。
- 遵守规范,但不拘泥。
- 适度灵活。
- RequireJS - require 使用方法特别灵活
- 关注点不同
- RequireJS - 兼顾 浏览器 、 Rhino 和 node
- Sea.js - 只关注 浏览器
# CommonJS & ES6 Module
# CommonJS
2009年,nodeJS 诞生了,服务端代码需要跟本地文件系统交互,跟网络层面交互,等等,模块化成为必然,CommonJS 算是真正意义上的比较完善的 js 模块化方案
这里需要特别强调一下,CommonJS 模块化规范规定的是在 运行时 的模块加载规范,即在运行时即用即加载,并缓存
# 意义
- 为了让Node.js的文件可以相互调用,Node.js提供了一个简单的模块系统
- 模块是Node.js应用程序的基本组成部分
- 文件和模块是一一对应的,一个Node.js文件就是一个模块
- 这个文件可能是JavaScript代码、json或者编译过的C / C++扩展
- Node.js中存在4类模块:原生模块和3种文件模块
# 模块加载 - require 方法
- 传参方式
require方法接受以下几种参数的传递:http、fs、path等,原生模块./mod或者../mod,相对路径的文件模块/pathtomodule/mod,绝对路径的文件模块- mod,非原生模块的文件模块
- 加载流程
- 从文件模块缓存中加载
- 从原生模块加载
- 从文件加载
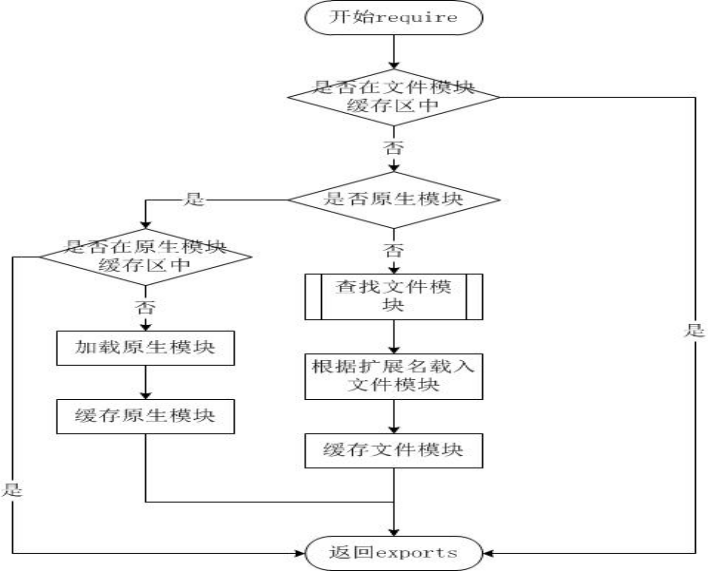
- 模块缓存
- 每次加载一个模块都会被缓存,这意味着 CommonJS 是运行在运行时修改模块状态的
- 所有缓存的模块都保存在 require.cache 中,以模块的绝对路径作为 key 缓存该模块导出的值
- 这意味着:俩模块名相同,但是保存在不同的路径,对 require 命令来说就是不同的模块,会重新加载
# 模块定义 - module 对象
- module.id - 模块的识别符,通常是带有绝对路径的模块文件名。
- module.filename - 模块的文件名,带有绝对路径。
- module.loaded - 返回一个布尔值,表示模块是否已经完成加载。
- module.parent - 返回一个对象,表示调用该模块的模块。
- module.children - 返回一个数组,表示该模块要用到的其他模块。
- module.exports - 表示模块对外输出的值。
exports- 为了方便,Node为每个模块提供一个exports变量,仅仅是 module.exports 的一个引用,在模块内部对外提供接口
# ES6 Module
正统的 JS 模块化规范,在之前的规范中对于js只有一种源文件—— 脚本(主动的代码段),ES6 出现之后,新出现了一种源文件形式—— 模块(被动的代码段)。引入模块方式如下(即指定解析目标为模块)
<script type="module" src="xxxxx.js"></script>
以下为 ESM 解析原理
# 名词
- 运行时环境 - 浏览器 或者 Node
- 加载器 - 由 运行时环境 提供,用于从模块定位符(url)加载资源
- 入口文件 - 指定为入口的脚本,从这个入口文件开始运行时环境会顺着导入语句找出所依赖的其他代码文件
- 模块定位符 - 模块导入、导出时的模块路径,浏览器中一般为 url ,node 中一般为本地文件的路径
- 模块定位算法 - 每个平台都有自己的一套方式来解析模块定位符。这些方式称为模块定位算法
- 模块记录 - 构建阶段产物,是模块协议将得到的js文件(字符串)解析成浏览器(运行时环境)能理解的一种数据结构
- 模块环境记录 - 管理 模块记录 的所有变量,跟踪每个导出对应于哪个内存地址
- 解析目标 - 解析一个js文件需要指定 解析目标 , 解析目标 不同解析的结果也不同,指定
type="module"(node中指定后缀.mjs文件)可以将js文件以模块的文件类型解析,规范中规定 ES6 所有的模块都按照 严格模式 来解析 - 链接 - 发生在实例化阶段,即将各个 模块记录 依照导出、导入语句与内存地址组合起来
- 代码 - 即指令集合,描述计算机该如何运行
- 状态 - 即变量在任何时候的真实值,存储在内存中
- 模块实例 - 运行阶段的产物,指 代码 与 状态 的结合,即指令集和变量值的结合。
几个注意点:
- ESM 规范规定了模块的解析、实例化、如何运行,并没有规定模块的下载(加载),下载过程是当前运行时环境规定的(提供的加载器),浏览器中根据
<script>URL地址去加载模块文件,node中为文件系统的本地文件 - 引擎是被动的,它提供各种接口(包括 ParseModule、Module.Instantiate 和 Module.Evaluate 等等),是运行时环境控制引擎什么时候该做什么
# 解析流程
模块规范要做的事情就是将加载过来的js文件(字符串)转换成引擎能够使用的模块实例(指令集和变量值),esm 分三个阶段(commonJS同步进行,即用即加载)
- 构建阶段 - 查找,下载,然后把所有js文件(字符串)解析成一堆 模块记录
- 实例化 - 为所有模块根据模块环境记录分配内存空间(此刻还没有填充值),然后依照导出、导入语句把模块指向对应的内存地址。这个过程称为链接
- 运行 - 运行代码,从而把内存空间填充为真实值,生成多个 模块实例
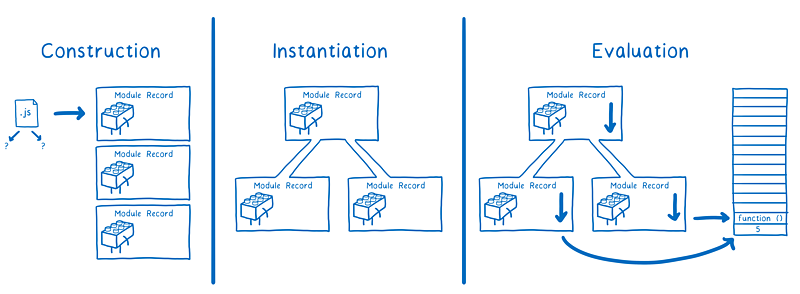
为什么node环境中模块的加载到解析运行,都是同步的,而浏览器中需要分不同阶段处理呢?
原因是两个运行时环境的 模块定位算法 不同:
- node环境 - 资源加载依赖本地的文件系统,因此构建、解析到运行都可以同步进行
- 浏览器环境 - 不同于node环境,资源的加载需要从网络上下载,同时UI渲染与JS引擎使用的是同一主线程,解析时间过长势必导致UI卡顿,因此浏览器环境将算法分为三个阶段,在构建阶段只是单纯的构建 模块记录 ,并不完全解析模块完整代码
# 构建
主要的目:使得运行时环境在不用完整解析模块实例,理解模块关系图 !
构建又分为三个步骤:(前两步都依靠运行时环境处理,生成模块记录是运行时环境控制引擎完成的)
- 确定要从哪里下载包含该模块的文件,也称为模块定位(Module Resolution)
- 提取文件,通过从 URL 下载或者从文件系统加载
- 解析文件为模块记录
- 动态导入
构建阶段由于只建立一堆模块记录,此时变量是还没有值的(还未分配内存),因此不支持动态导入 (与 commonJS 不同)可以使用import someModule from `/path/${someModule}` // Error !import()语法实现动态导入依赖,引擎会将加载的文件当成了一个新的入口文件,动态导入的模块会开启一个全新的独立依赖关系树 - 加载器加载模块
加载器使用模块映射管理缓存,即 K-V 模型,key 为 URL,加载完成之前 value 标记为加载中,加载完成之后 value 为生成的模块记录 - 解析模块
引擎根据解析目标解析js文件,type="module"将作为模块解析
# 实例化
主要的目:单独的 模块记录 之间是没有关联关系的,实例化过程即建立模块之间的关联关系 !所有导出的函数声明都在这个阶段初始化
- 实例化顺序:引擎会采用深度优先的后序遍历方式,这意味着将从关系图到达最底端没有任何依赖的模块,然后设置它们的导出
- 简单理解就是:A 中 import 依赖 B ,链接 过程即将 B 的导出,导入到 A 中,连接内存地址(此时还没有值)
- 注意此处导出与 commonJS 的不同:
- commonJS 为值拷贝,即导出的内容与模块的内容内存地址不相同,在导入依赖的地方将变量重新赋值并不会抛出异常
- ES Module 为值引用(实时绑定),即导入、导出所使用的变量是同一块内存地址
这样做的好处是:使得引擎可以在不运行任何模块代码的情况下完成链接,对解决运行阶段的循环依赖问题有一定帮助
# 运行
主要的目:往已申请好的内存空间中填入真实值 !使得模块完全可用
- 运行顺序:引擎会采用深度优先的后序遍历方式,与实例化阶段一致
- 关于副作用:模块代码只会运行一次,因为在初始化的过程中可能会存在一些副作用(向服务器发送请求之类的)
- 关于循环引用:由于 esm 使用的导出方式是值引用,因此对于循环引用,模块拿到的值始终是同一份,可以理解为实时的,因此循环引用这点在 esm 中支持的比较好(也正是由于循环引用问题,esm 在设计之初就考虑到了,因此这也是浏览器环境将 模块定位算法 分段的原因之一)
# CJS vs ESM
个人理解:commonJS 设计初衷是为 nodejs 提供模块化支持,其模块加载原则是即用即加载,无需考虑网络层的时间消耗。ES Module 则设计用来支持浏览器端的模块化需求,从底层设计上对 模块定位算法 的分段,以及导入导出机制等等,都是为浏览器环境的运行机制所做出的调整
- 模块定位算法不同(由于所属环境差异,考虑性能使得资源加载的方式有不同)
- cjs - 各阶段完全同步进行,可以理解为运行时模块化方案
- esm - 分三阶段,构建阶段只解析js文件生成模块记录,实例化阶段生成模块记录直接的关联关系,运行阶段
- 模块定位算法不同导致模块协议对于动态导入支持不同
- cjs - 各阶段同步进行,运行时变量即有值
- esm - 导入语法解析在构建阶段,此时变量还未分配内存,因此不可用使用变量动态导入模块(可以依靠
import()语法实现动态)
- 模块导出的机制不同
- cjs - 导出为 值拷贝 ,即不保存模块状态
- esm - 导出为 实时绑定 ,导出和导入的模块都指向相同的内存地址,同时导入为只读,即 import 进来的引用类型不能重新赋值
- 模块导出的机制不同导致对于循环引用的处理方式不同
- cjs - 不支持循环引用,导出机制受解析顺序控制,若循环引用的模块未加载完,拿到的值为
undefined - esm - 支持循环引用,导出机制为值引用,为实时值
- cjs - 不支持循环引用,导出机制受解析顺序控制,若循环引用的模块未加载完,拿到的值为
# 其他的模块化方案
# umd
该模块是可同时兼容浏览器端与服务端的模块化方案,形式为如下
(function (global, factory) {
typeof exports === 'object' && typeof module !== 'undefined' ? module.exports = factory() :
typeof define === 'function' && define.amd ? define(factory) :
(global.libName = factory());
}(this, (function () { 'use strict';})));
// 翻译一哈
(function (global, factory) {
// 判断 exports 、 module 是否存在
((typeof exports === 'object') && (typeof module !== 'undefined')) ?
// 是,即为 node 环境(commonJs)
(module.exports = factory()) :
// 否,判断 define 、define.amd 是否存在
((typeof define === 'function') && define.amd) ?
// 是,即为 浏览器 环境
define(factory) :
// 否,撒也不似
(global.libName = factory());
}(this, (function () { 'use strict';})));
// 运算符优先级
// ... ? ... : ... < && < === < = < typeof